
2 Minutes to See How Discovery Program Transforms You
What's New


RECENT STORY
Bridging Educational Gaps: UC Berkeley's Data Science Discovery Program Extends DataJam to Local Community Colleges

A Glimpse into Discovery


3000+
Student Researchers
1000+
Research Projects
2015
Established in

Over 100+ companies or NGOs joined us
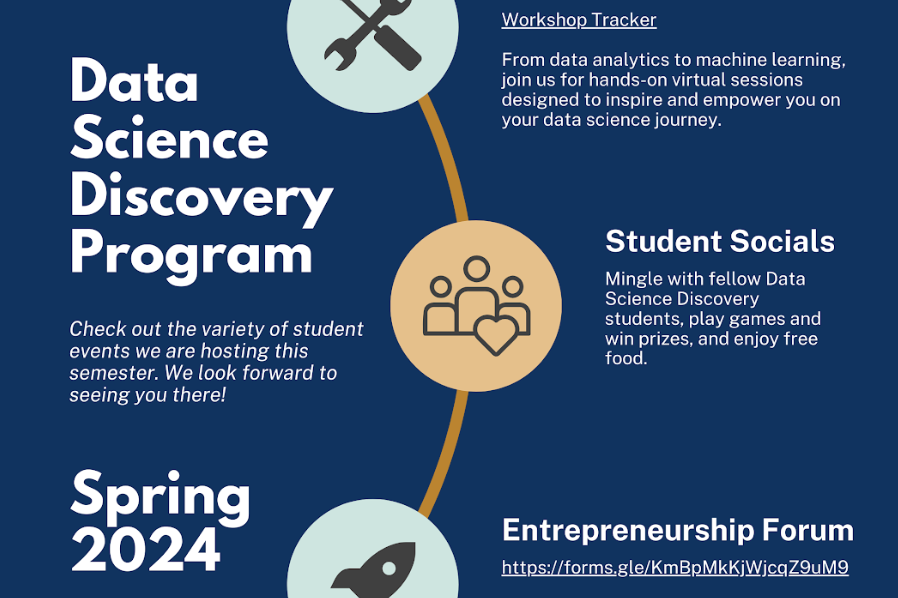
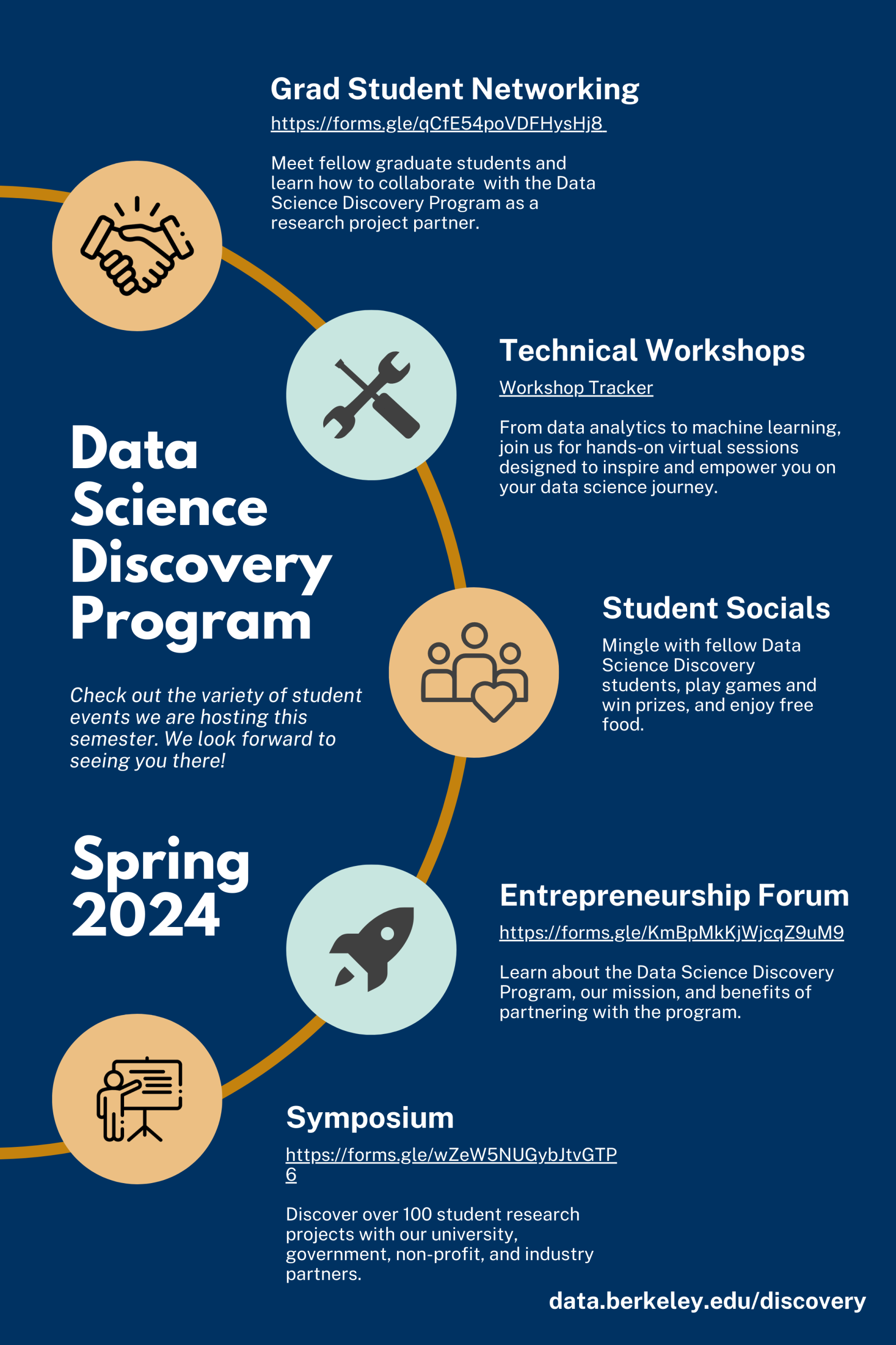
Program updates
Program offerings

Projects
Student researchers have the opportunity to work on semester-long discovery projects of their choice and apply data science to real-world problems with a variety of companies, from startups to NGOs to well-established corporations.

Showcase events
Each semester, we host a showcase that attracts over 500 participants, including students, industry partners, and academicians. It is a fantastic opportunity to showcase your projects to people from different fields.

Professional support
Our data science consulting teams offer a wide range of professional workshops and one-on-one consulting to help our student researchers gain valuable technical skills and real-time support. Some past workshop topics include: machine Learning, web scraping, and data visualization.

{kind=link}
Cloud computing resources
Discovery partners and students for the Fall 2023 semester can request cloud computing credits. We offer several options and resources for cloud computing, including Savio, UC Berkeley's Linux cluster with high-speed, low-latency networking and a high-speed parallel file system for high performance computing.
How to get involved?
![]()
For partners
Companies, NGOs, governments, and academic partners
We are looking for companies and nonprofits with exciting projects to collaborate on. Please reach out if you have a project for us!
![]()
For students
Undergraduate and graduate
We are looking for students who are eager to learn and passionate about applying data science to technology. Interested? Join our program!